Like many organizations, we are also using Oracle eBusiness Release 12.2, more specifically 12.2.7. But, as per Oracle we are far behind from latest stable release. Because of on-going priority tasks, we cannot upgrade our system, thus missing many critical bug fixes as well as productivity and performance fixes.
If your application is recording high volume transactions and not using Oracle Advanced Supply Chain Planning (ASCP) but using ATP for Sales Orders Scheduling and Global Order Promising, then you are in the same boat like us. We have third party cloud-based planning application called O9. Demand and Supply planning are performed there based on the collected data from multiple ERP systems including Oracle eBS. Though we are not using Oracle Configurator for configured items, we have developed a home-grown Item on the Fly (IOTF) solution which creates an item based on the user preferences during Order Entry. This along with multiple warehouses across the globe created millions of items in our system.
Since, we want to provide customers most accurate planned schedule ship date, we are using ATP. To schedule these newly created items, we have the requirement to run ATP Data Collection and Schedule Order Program quite frequently. On the other hand, 90% of our orders are fulfilled within a week or so. This means that if we do not run ATP Data Collection for Complete Refresh quite frequently then MSC demand table entries become obsolete. These two dual critical requirements have put us in a challenging situation.
Our installation is centralized, meaning data is collected from transactional system and ATP calculation is done on the same system. Overall process could be depicted by simple picture like below

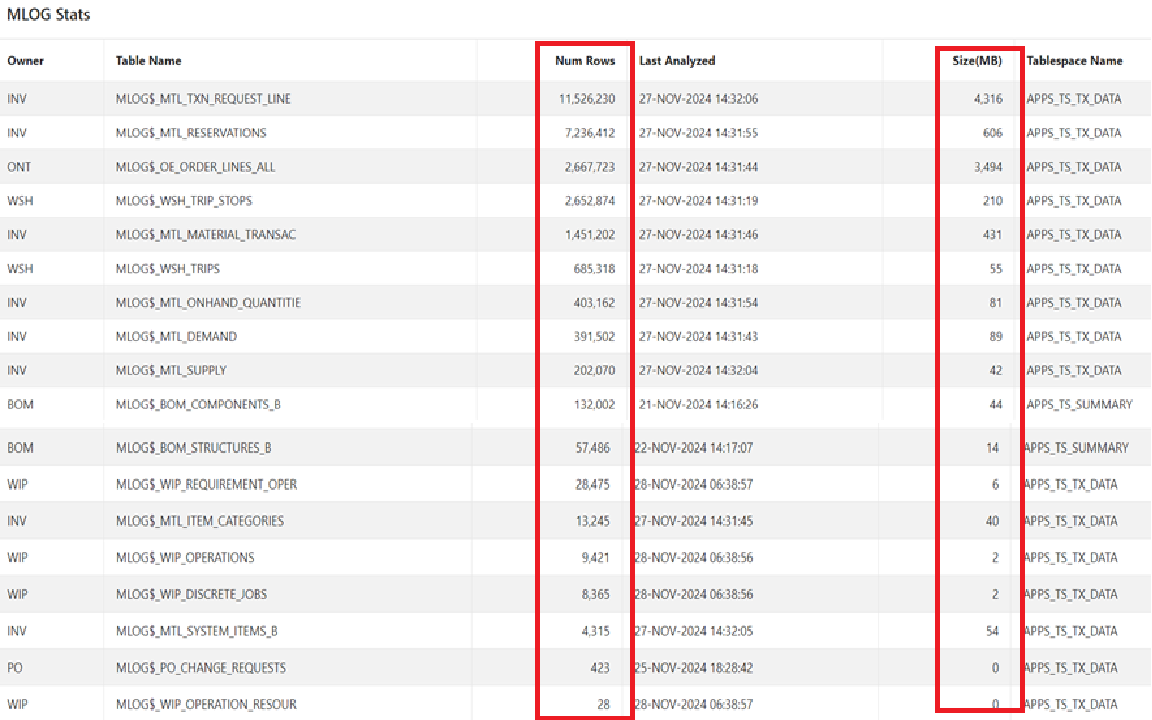
- Net Change Refresh - This is Collecting the changed records. It is accomplished by identifying, recording and subsequently processing the changed records in an efficient way. Oracle does it by using Database mechanism - MLOG tables. These are Materialized View Log tables associated with base eBusiness master and transactional tables like OE_ORDER_LINES_ALL, MTL_SYSTEM_ITEMS_B, MTL_TXN_REQUEST_LINES etc. When Net Change Refresh is performed, Oracle scans these MLOG tables and then pushes them to Snapshot tables or Materialized Views (MV). Refresh Collection Snapshot program is the one which performs this activity. Once done, the processed records are deleted from MLOG tables.
- Complete Refresh - Collecting fresh set of data from Oracle base application tables based on the criteria defined by Oracle. These criteria are maintained in Snapshot tables which are nothing but Materialized Views. Each of the Materialized Views is having an underlying SQL Query with filter criteria. Complete refresh bypasses MLOG tables. It refreshes the snapshot tables (MVs) by running the query. Again, same Refresh Collection Snapshot program does this job. Once done, it then deletes the MLOG tables to mark the starting point for changed records.


SELECT DISTINCT
amdr.MVIEW_NAME "Snapshot",
amdr.OWNER "Snapshot Owner",
amdr.DETAILOBJ_NAME "Base Table Name",
amdr.DETAILOBJ_OWNER "Base Table Owner",
log_table mlog$_name
FROM ALL_MVIEW_DETAIL_RELATIONS amdr,
dba_snapshot_logs dsl
where DETAILOBJ_TYPE = 'TABLE'
and (detailobj_owner, detaiLobj_name) not in (('MSC','MSC_COLLECTED_ORGS'))
AND amdr.DETAILOBJ_NAME = dsl.MASTER
and DETAILOBJ_NAME in
('AHL_SCHEDULE_MATERIALS','BOM_COMPONENTS_B','BOM_CTO_ORDER_DEMAND','BOM_DEPARTMENTS','BOM_OPERATIONAL_ROUTINGS','BOM_OPERATION_NETWORKS',
'BOM_OPERATION_RESOURCES','BOM_RESOURCE_CHANGES','BOM_RES_INSTANCE_CHANGES','BOM_STRUCTURES_B','BOM_SUBSTITUTE_COMPONENTS',
'BOM_SUB_OPERATION_RESOURCES','CSP_REPAIR_PO_HEADERS','EAM_WO_RELATIONSHIPS','MRP_FORECAST_DATES','MRP_FORECAST_DESIGNATORS','MRP_FORECAST_ITEMS',
'MRP_SCHEDULE_DATES','MTL_DEMAND','MTL_ITEM_CATEGORIES','MTL_MATERIAL_TRANSACTIONS_TEMP','MTL_ONHAND_QUANTITIES_DETAIL','MTL_RELATED_ITEMS',
'MTL_RESERVATIONS','MTL_SUPPLY','MTL_SYSTEM_ITEMS_B','MTL_TXN_REQUEST_LINES','MTL_USER_DEMAND','MTL_USER_SUPPLY','OE_ORDER_LINES_ALL','PO_ACCEPTANCES',
'PO_CHANGE_REQUESTS','PO_SUPPLIER_ITEM_CAPACITY','WIP_DISCRETE_JOBS','WIP_FLOW_SCHEDULES','WIP_LINES','WIP_MSC_OPEN_JOB_STATUSES','WIP_OPERATIONS',
'WIP_OPERATION_NETWORKS','WIP_OPERATION_RESOURCES','WIP_OP_RESOURCE_INSTANCES','WIP_REPETITIVE_ITEMS','WIP_REPETITIVE_SCHEDULES','WIP_REQUIREMENT_OPERATIONS',
'WIP_SUB_OPERATION_RESOURCES','WSH_DELIVERY_DETAILS','WSH_TRIPS','WSH_TRIP_STOPS','WSM_COPY_OPERATIONS','WSM_COPY_OP_NETWORKS','WSM_COPY_OP_RESOURCES',
'WSM_COPY_OP_RESOURCE_INSTANCES','WSM_COPY_REQUIREMENT_OPS')
order by MVIEW_NAME; -- replace this line to use OPTION B or C
-- order by log_table, mview_name -- OPTION B sort by MLOG Name
-- order by DETAILOBJ_NAME, mview_name -- OPTION C sort by Base Table Name


Take the backup of the original file mv MSC_TOP/sql/MSCONTSN.sql $MSC_TOP/sql/MSCONTSN.sql.orig.
- Run Create OE Snapshots. Once the program completes, it sets the MSC: Source Setup Required to Yes. You need to manually set this back to No. Otherwise ATP Data Pull program will Submit Create AHL Snapshots to re-create all snapshots. Since, we modified only OE one we don't need to re-run it again.

- Set the profile option MSC: Source Setup Required to Yes and then Submit ATP Data Pull program. This will re-create all snapshots based on new definitions. Four our case only OE Snapshot definition has changed.

No comments:
Post a Comment